重磅!琶洲实验室团队开源全新算法NLFT实现LLMs平民化,性能倍数超越强化微调ReFT
近日,由琶洲实验室联合华中科技大学、华南理工大学科研团队在小样本微调领域取得重要进展。论文“Natural Language Fine-Tuning”提出了一种简单、低成本且极大提高准确率的全新方案——自然语言微调(NLFT)。NLFT大幅降低了大语言模型(LLM)的准入门槛,摆脱对数据量和算力资源的依赖,使LLM实现了平民化。目前,团队已经开源了所有的代码、数据、模型,以供研究者在此基础上探索改进,并确保论文中每个数据点真实可复现。
论文链接:
https://arxiv.org/abs/2412.20382
Github链接:
https://github.com/Julia-LiuJ/NLFT
相关背景:12月6日,OpenAI 推出强化微调(Reinforcement Fine-Tuning)技术引发广泛关注,可以使用极少训练数据即在特定领域轻松地创建专家模型。OpenAI CEO Sam Altman将其称之为“2024年最大的惊喜”。在这项工作中,开发者只需提供几十个高质量任务,即可通过强化微调定制领域专家模型。强化微调能够提升模型在处理领域问题时的推理能力,并提高在特定任务上的准确性。对于那些要求高精度和专业知识的领域,强化微调能够发挥至关重要的作用。

近一个月层出不穷的热点讨论,充分展示了这项工作带给了开发者巨大惊喜。OpenAI提供了一种行之有效的小样本微调示范,利用强化学习技术提高将LLM运用到各细分领域的效率。目前,强化微调研究计划已宣布进入Alpha阶段,将于2025年第一季度公开发布。于此同时,字节跳动称该思路与其在ACL 2024发表的Oral论文相同。在这篇早先发表的论文中,探索了将SFT与Reinforcement Learning相结合应用于数学推理任务的途径。

根据琶洲实验室团队论文显示,NLFT在LLM的小样本微调任务上,已经从准确率、训练时间、显存占用等多角度成倍超越目前领先的强化微调技术(ReFT,字节跳动,ACL2024)。参考OpenAI在今年12月宣传但未发布模型的强化微调技术原理,RFT的算力成本将会是NLFT的几倍或几十倍,在准确率性能上的差距仍待考证。
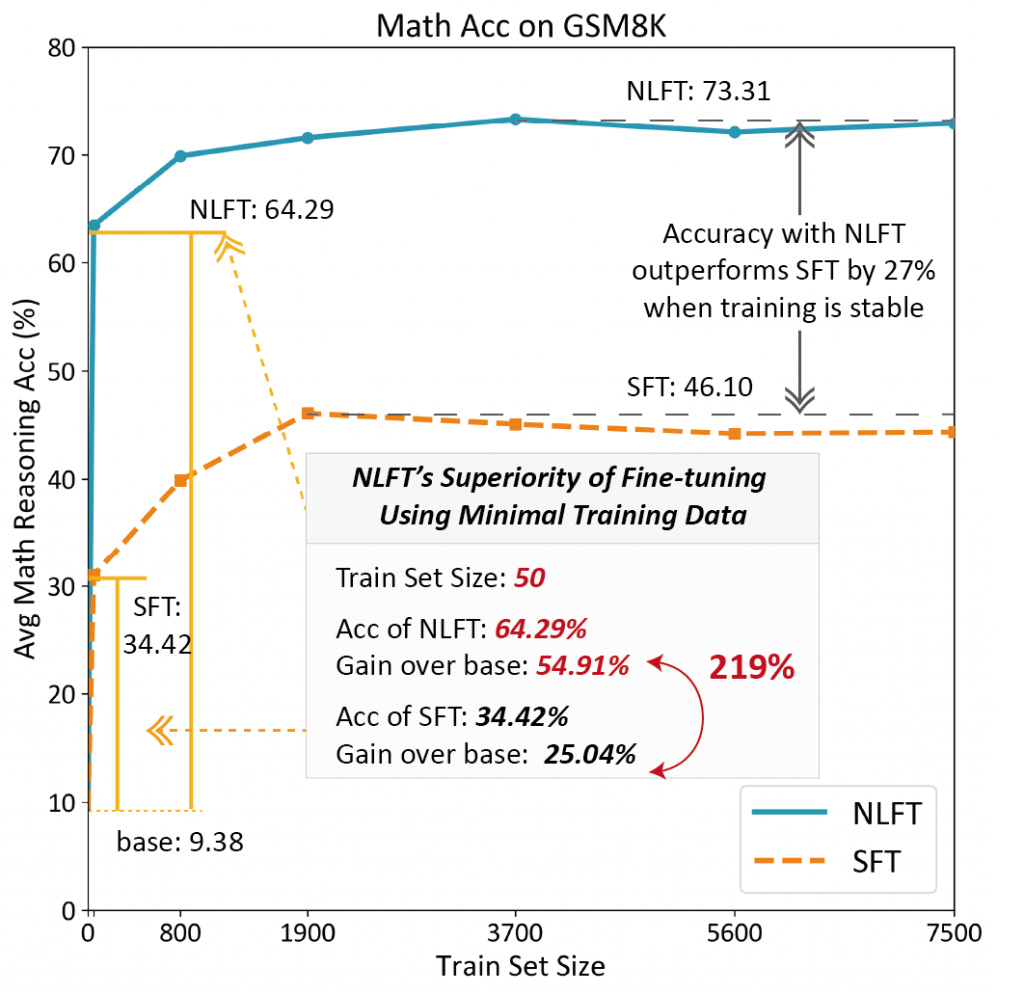
NLFT仅用50条随机训练数据,短短3轮训练,不到5分钟的时间和44.46 GB的GPU显存,就将准确率只有9.38%的基础LLM(Llama3-8b)的准确率在GSM8K数据集上的准确率提升到 64.29%。准确率增量超过SFT 219%。与ReFT相比,时间复杂度和空间复杂度分别降低了 78.27% 和 92.24%。
一、摘要
在大语言模型应用于细分领域微调任务时,由于特定领域知识数据的缺失,现有的大模型微调技术面临前所未有的挑战。大模型微调通常依赖于大量标注数据,并且需要借助外部指导与反馈,如人类对齐、标量奖励、标签奖励和示范等。然而,当面对特定领域专业问题的数据不足时,这些方法往往显得力不从心。本文针对小样本数据进行的细分领域微调任务,首次提出了一种利用自然语言进行微调的方法,称为自然语言微调(Natural Language Fine-Tuning,NLFT)。通过直接利用目标语言模型对语言的深刻理解能力,NLFT将自然语言的指导范式嵌入到token级输出中,在这一过程中,通过计算概率发现重要的token。由于在NLFT中语言信息得到了高效利用,我们提出的方案在节省训练成本的同时,能显著提升训练效果,从准确率、节省时间、节省计算资源这三个方面全面超越强化微调(ReFT)。此外,从宏观角度看,该方案可以被视为对SFT过程进行了token级细粒度优化,从而无需进行多轮预热即可高效替代SFT(而ReFT通常需要通过SFT进行多轮预热)。相比SFT,NLFT并未增加算法复杂度,保持O(n)的时间复杂度。在GSM8K数据集上的充分实验结果表明,NLFT仅用50条数据,其准确率超过SFT的219%。与ReFT相比,NLFT在时间复杂度和空间复杂度上分别降低了78.27%和92.24%。NLFT的优越性为在资源受限的网络边缘部署各类创新的LLM微调应用铺平了道路。
二、NLFT的核心理念
我们可以通过形象的类比,阐述NLFT与SFT和ReFT之间的区别:

我们将大型语言模型类比于学生,而LLM的微调过程类似于学生的学习过程。SFT(监督式微调)、ReFT(基于强化学习的微调)和NLFT(自然语言微调)代表了学生三种不同的学习过程。
以数学推理为例,在SFT中,学生以鹦鹉学舌的方式学习,即在抄写了大量问题和标准答案对之后,期望学生在看到某些特定问题时能够写下预定的答案。
在ReFT中,学生首先通过几个周期的SFT获得解决数学推理问题的基本技巧。然后,为了进一步提高技巧,ReFT要求学生提交包含引导数学问题解决方案详细分析的答案卷。通过与标准答案比较,每个答案卷都会得到一个总的分数。通过这个分数,学生调整数学推理的策略,通过强化学习机制习得推理能力。由于学生的目标是尽可能获得高分,因此需要多轮提交答案卷并从评估系统中获得反馈。
而在NLFT中,学生通过从详细批改出得分点与失分点的答卷中学习。与SFT需要预热的过程不同,NLFT省去了预热环节,学生直接提交“答卷”。通过将目标模型自身作为自然语言评价器,可以实现对学生的答题过程细粒度的分析,标注出得分点与失分点,同时也不需要任何额外的外部指导。初期如果这个学生是“学渣”,他会通过示范案例来学习,即学习那些高分考生的答卷内容,这种方式可以在短期内显著提升他的能力。相反,如果这个学生一开始表现很好,他可以通过自学,即从自己的答卷中总结经验,巩固已有知识点,同时避免失分点(类似于不断刷题)。通过这种“双重学习”(Dual Learning)过程,NLFT展现出了颠覆性的效果。
三、NLFT方法简析
NLFT的核心方法可以被简化成一个相当易于理解的过程。首先为准备阶段,数据集输入分为“问题”,针对“问题”的“标准答案”和针对模型输出的错误回答的“评价”。
在得到系统的输入后,模型开始微调。大语言模型首先接收“问题”并给出回答Y={y1,y2,…,yn},并记录回答中各个token的条件概率P(yt|X,yt-)。在此之后,模型会判定此回答为“正确”的还是“错误”的。
当回答是正确的时,模型会分别记录回答Y的各个token在问题条件Xbase={Question}和标准答案环境下Xstandard={Question, Standard answer}下的条件概率,并对他们的条件概率进行对比。当一个token的标准答案条件概率高于问题条件概率时,我们会将其归类为“重要得分点”,并对其在损失函数中的权重进行调高。同时,围绕着这个“重要得分点”,我们也会对周边信息进行语义聚类,以划分出“次要得分点”,并同样对其权重进行调整。
而当回答是错误的时,模型则会分别记录回答Y=在问题条件Xbase={Question},判断环境下Xjudge={Question, Judgement}和标准答案环境下Xstandard={Question, Standard answer}下的条件概率。在此之后,我们会分别将判断环境条件概率与回答条件概率和标准答案条件概率进行比值对比。当一个token两个比值都很高(也就是说,此token在判断环境下的出现概率高于问题环境和标准答案环境)、且判断条件概率本身不低于阈值时,我们将其归类为“重要失分点”,并对其在损失函数中的权重进行调高。同时,围绕着这个“重要得分点”,我们也会对周边信息进行语义聚类,以划分出“周边错误区”,并同样对其权重进行调整。
在得到了得分点和失分点的定位和权重调整后,我们会将其整合到损失函数中来进行模型微调,重复以上步骤并得到最后的结果。


四、实验结果
我们在数学问题数据集 GSM8K 上进行 NLFT 的初步验证。GSM8K 数据集提供自然语言形式的问题、标准解题过程,以及数值形式的标准答案。GSM8K 训练集总共有 7473 条数据,测试集有 1319 条数据。
当需要微调的基础模型准确率较低时,我们选择使用其他性能更好的模型来生成回答。我们将这一过程称为“教学”。而当模型有能力生成一定比例的正确响应时,我们继续让训练好的模型从自己的答案中学习并产生结果。我们将这一过程称为自学。我们将我们的模型与SFT和ReFT进行了对比。
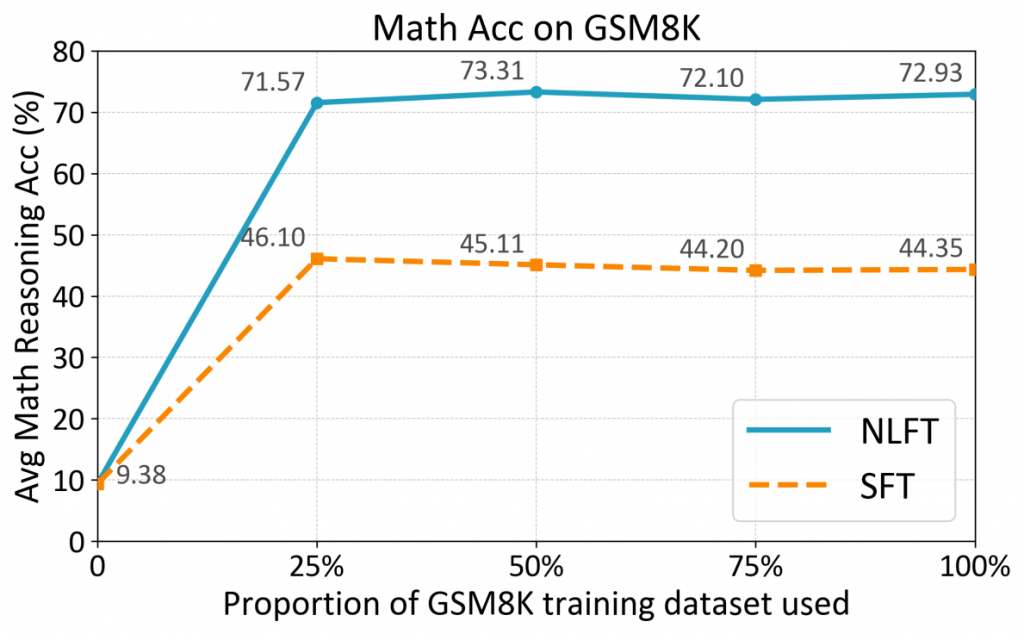
首先,我们对比了模型在完整数据集的表现。如图五所示,我们可以观察到NLFT始终实现比SFT更高的准确率,NLFT在所有四个百分比数据集上都实现了超过70%的准确率,而SFT则在44%到46%之间。相比SFT,NLFT的准确率的提高超过25%。此外,训练数据集比例的变化对NLFT和SFT的准确率影响很小,这表明通过扩大数据规模来提高准确率的边界效应将逐渐减少。因此,将我们将关注点转移到更小规模的训练数据集上,以填补从0到25%的准确率细节的空白。
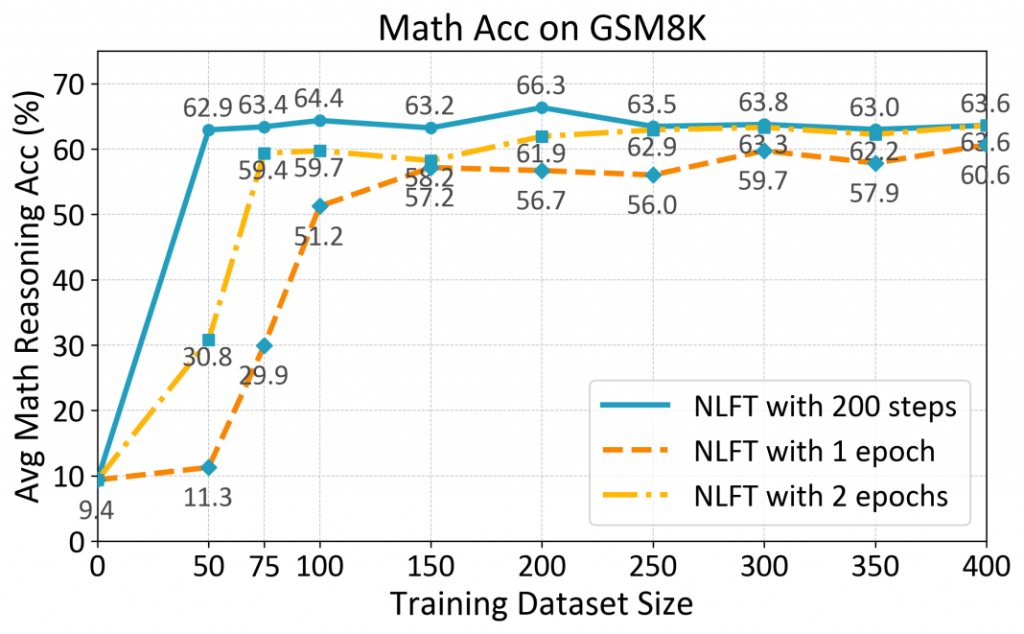
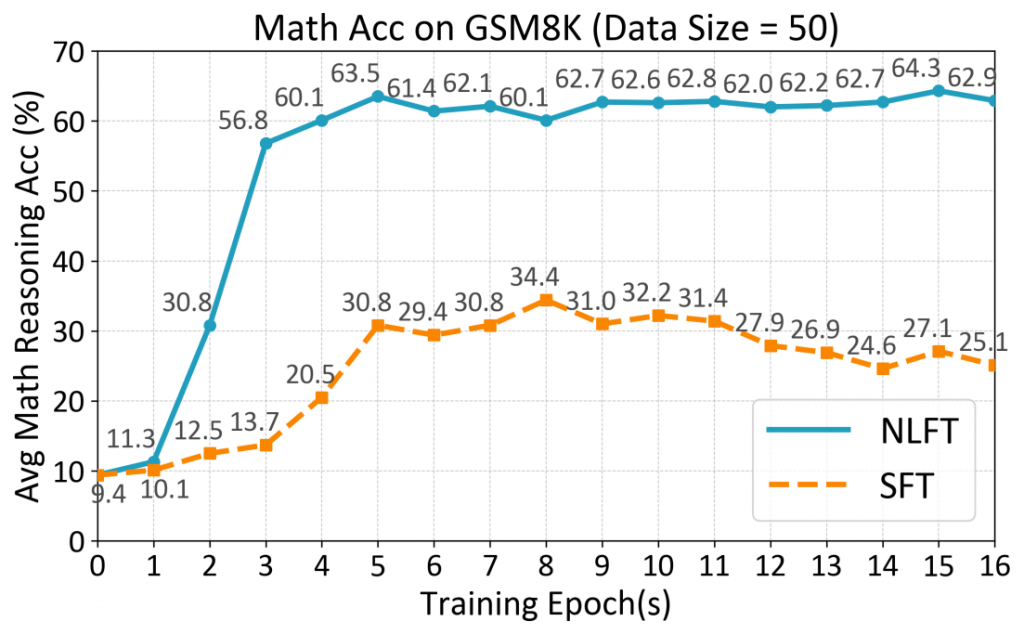
为了研究NLFT在将最小数据集样本用作训练集时的性能,我们采用了从50到400的数据大小,并每隔50个数据点进行划分。在图六中,我们在不同的数据大小下进行了固定训练步骤为200的实验。我们观察到,在50个数据下NLFT已经达到了62.93%的准确率,这接近于400数据下的准确度。图七比较了NLFT鱼SFT在连续16个epoch内的准确率。我们观察到,在第1个epoch时准确率为11.30%。到第2个epoch,它急剧上升到30.8%,这是SFT在第五个epoch才能达到的准确率。随后,模型准确率继续提高,在第4个epoch达到了60.1%,之后一直保持在60%以上。与此同时,SFT从第1个epoch到第5个epoch迅速上升,在第8个epoch达到了最高准确率34.4%,之后逐渐下降。这些结果表明,NLFT在有限的数据集上展示了突破性的学习潜力,这是SFT之类的微调算法所不具备的。
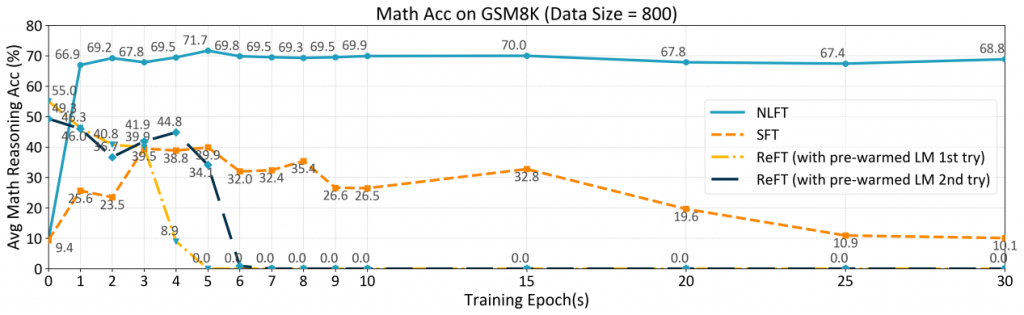
为验证不同微调算法在相同数据规模,相同训练程度下的表现效果,我们还开展了随机前 800 条数据下的实验,训练并测试得到 NLFT,SFT,ReFT 训练 30 个 epoch 的准确率,如图八所示。在实验中,由于ReFT 等基于强化学习的微调算法不稳定,对数据量有较大的要求,ReFT退化到只能复读 instruction。而 SFT 在 800 条数据的配置下能够正常学习,其间在 epoch 5 达到了 39.88% 的准确率,此后准确率有 30% 幅度的下降。相比之下,NLFT 不仅能够稳定训练,而且达到了 71.65% 的准确率,并在最高准确率后准确率仍然可以保持稳定。这说明了 NLFT 对数据规模的普适性与训练效果的高效性。
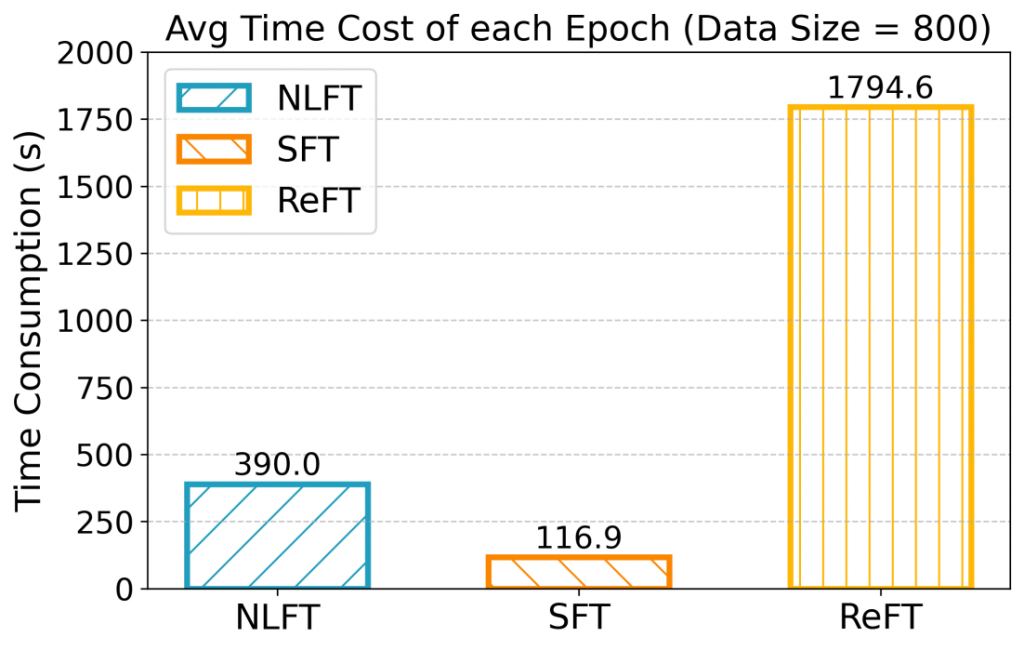
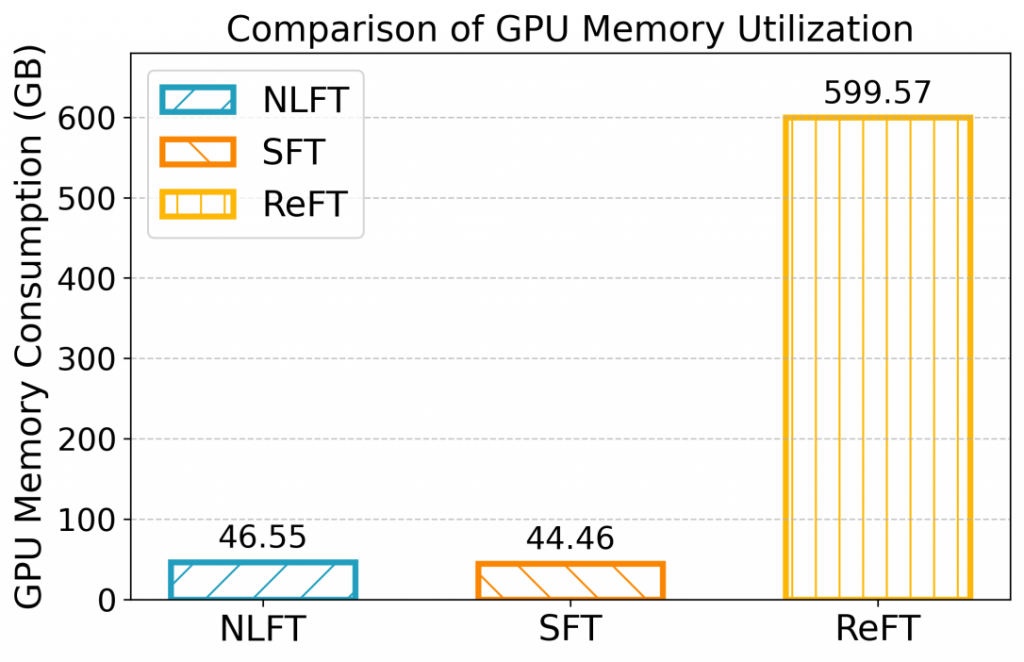
而在时间消耗与显存消耗方面,如图九与图十所示,在 2 卡配置下训练 1 个 epoch,SFT 平均需要 7.77 min,占用 44.55 GB 的总显存;NLFT 平均需要 26.1 min,占用 46.87 GB 的总显存;而 ReFT 无法在 2 卡配置下运行。在算法复杂度分析中,我们得知 NLFT 相比 SFT 多了 3 倍的前向推理过程,因此其时间复杂度的常数项至少为 3,这一点能从两者耗时的比值得到对照。即使增加了常数项,但 NLFT 仍然属于线性时间复杂度的轻量级微调算法。
五、总结
NLFT提出了一种针对自然语言的微调算法NLFT。算法对不同prompts条件下的各个自然语言token条件概率进行对比,直接将自然语言作为监督信号,对其中的saliency token进行定位并进行scale 赋值。实验结果表明,我们的算法与之前的算法相比,有更低的时间复杂度和更好的效果。理论上来说, NLFT算法该方法适用于所有能够通过 CoT 生 成 output,并具有标签数据的场景。例如,程序设计,医学诊断,自然语言推理,复杂问答系统等。通过将生成的output与标签对比,可以实现对于其中显著token的标注,从而应用NLFT算法实现token级别的微调。